🥪 下载星巴克产品图片
这个示例用于演示download()方法的功能。
✅️️ 页面分析
目标网址:https://www.starbucks.com.cn/menu/
采集目标:下载所有产品图片,并以产品名称命名。
如图所示:
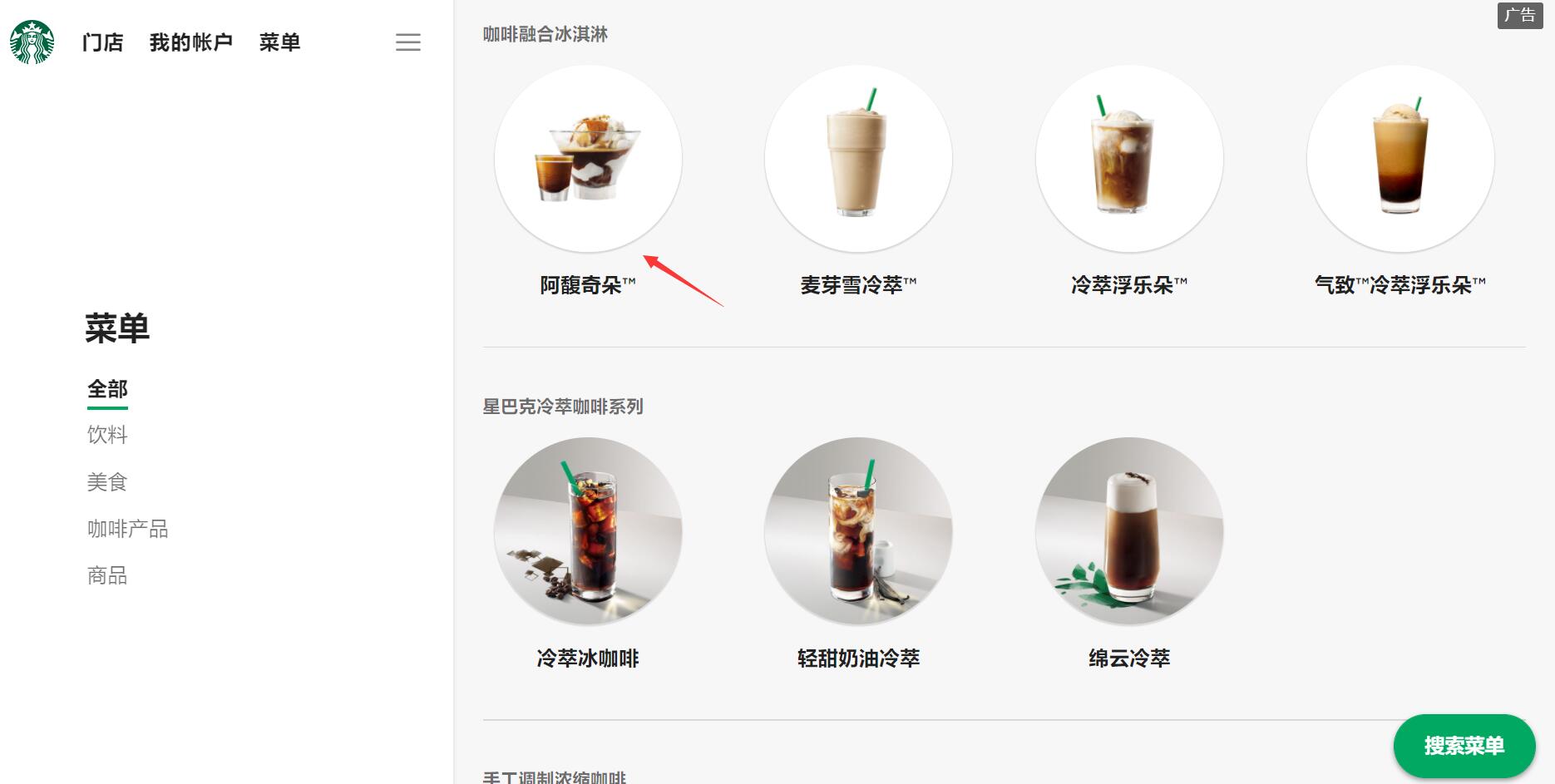
按 F12 查看页面代码,可以发现每个产品图片都是一个div元素,class属性都为preview circle。且图片网址藏在其style属性中。而产品名称则在这个div元素后面一个元素中。
如图所示:
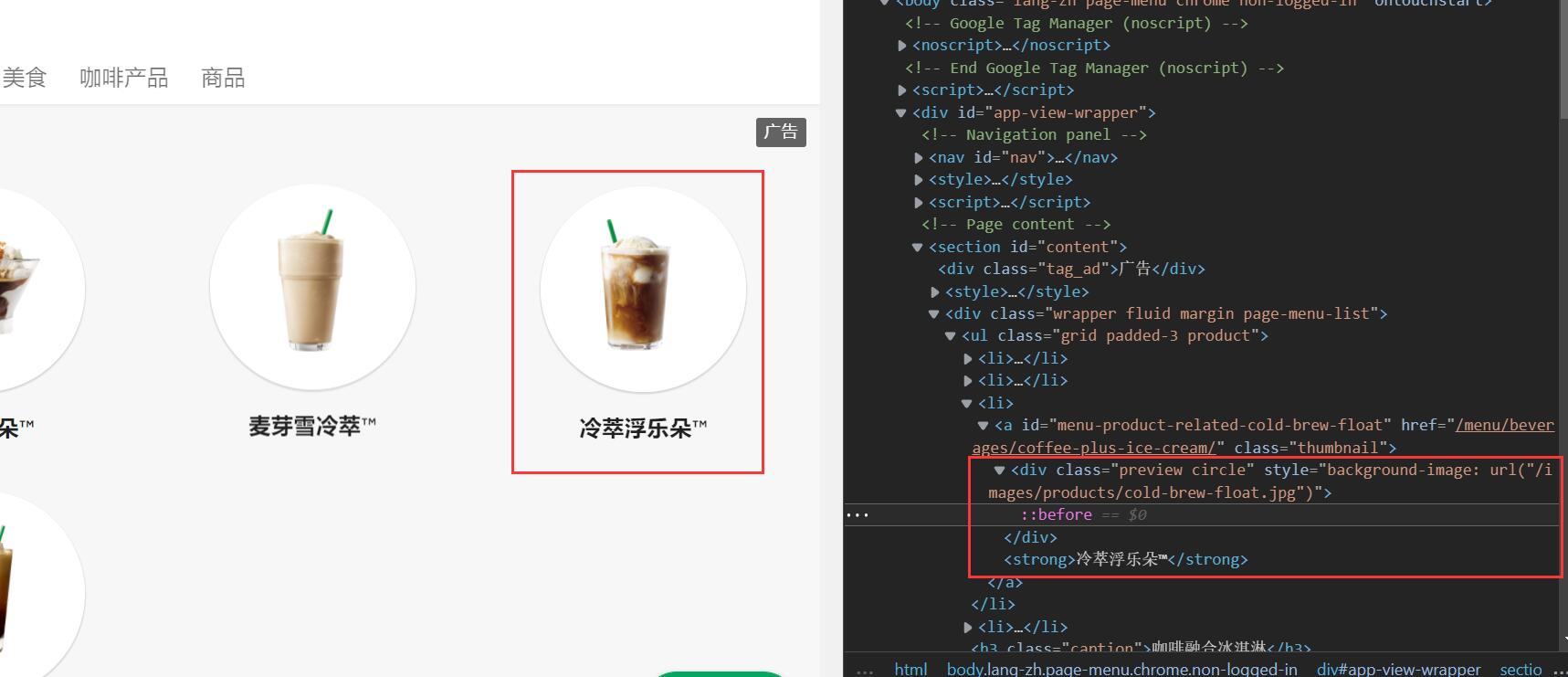
✅️️ 编码思路
按照页面规律,我们��可以获取所有class属性为preview circle的元素,然后遍历它们,逐个获取图片路径,以及在后面一个元素中获取产品名称。再将其下载。
并且这个网址页面结构非常简单,没有使用 js 生成的页面,可以直接使用 s 模式访问。
✅️️ 示例代码
from DrissionPage import SessionPage
from re import search
# 以s模式创建页面对象
page = SessionPage()
# 访问目标网页
page.get('https://www.starbucks.com.cn/menu/')
# 获取所有class属性为preview circle的元素
divs = page.eles('.preview circle')
# 遍历这些元素
for div in divs:
# 用相对定位获取当前div元素后一个兄弟元素,并获取其文本
name = div.next().text
# 在div元素的style属性中提取图片网址并进行拼接
img_url = div.attr('style')
img_url = search(r'"(.*)"', img_url).group(1)
img_url = f'https://www.starbucks.com.cn{img_url}'
# 执行下载
page.download(img_url, r'.\imgs', rename=name)
Tips
程序中无需创建imgs文件夹,download()方法会自动创建。
✅️️ 结果
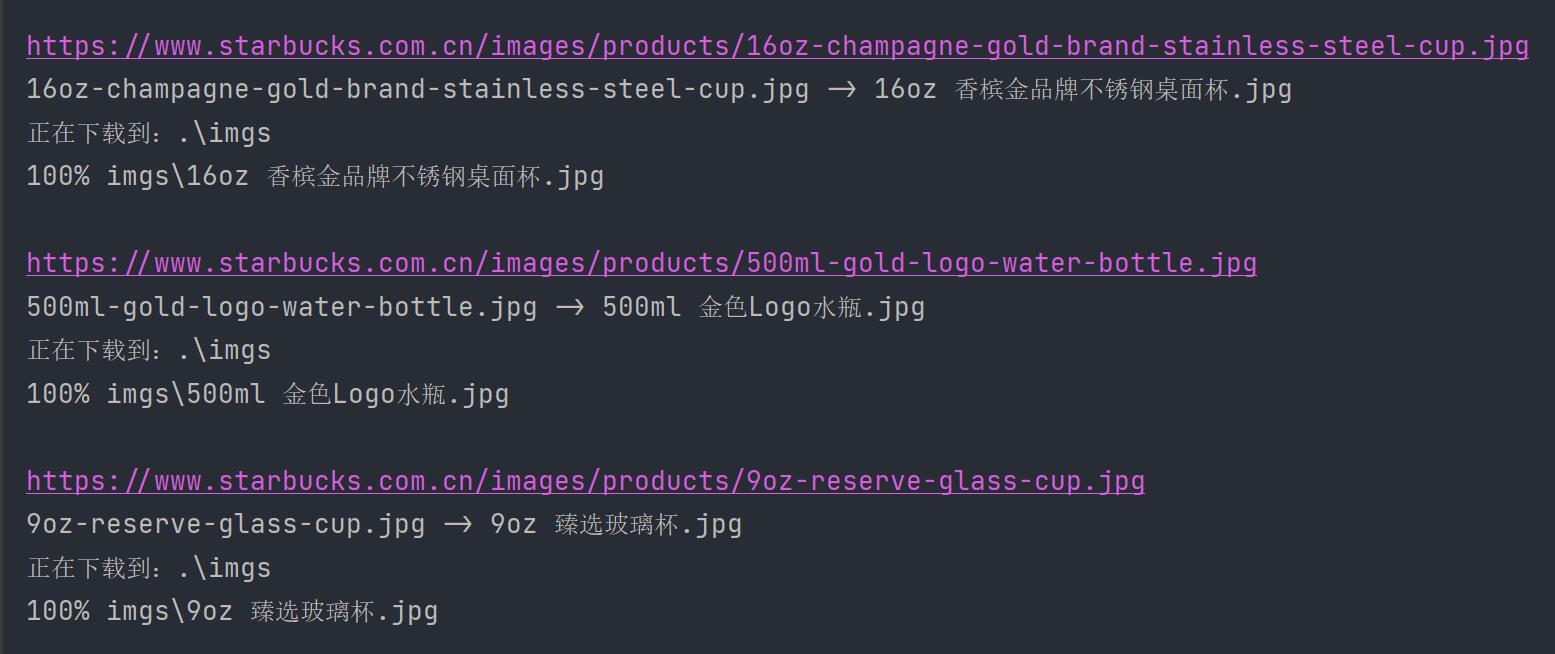
程序执行的时候,默认会把下载进度打印出来。
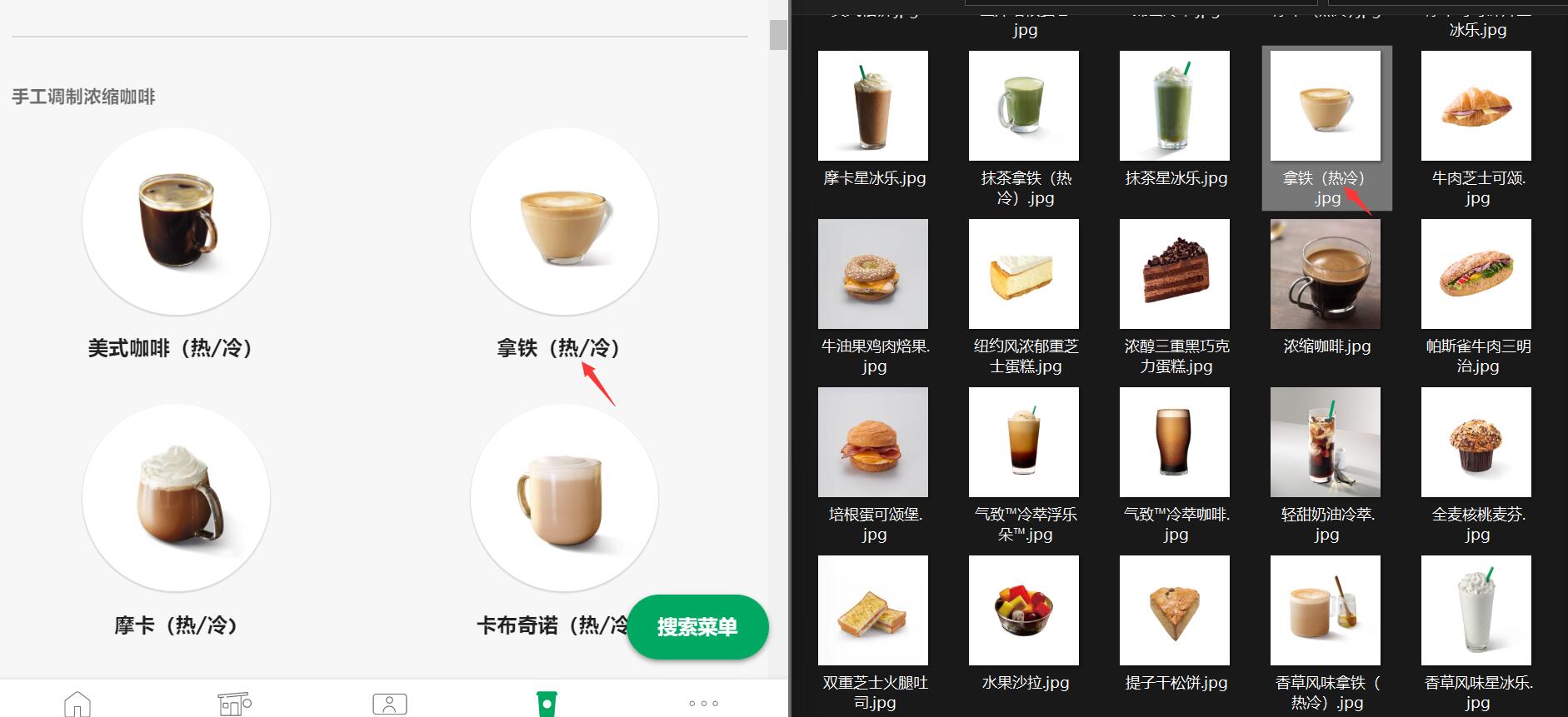
我们注意到有些产品名称是带有/的,这是系统路径的非法字符。一般下载方法需程序员自行处理。
但 DrissionPage 的download()方法自带去除非法字符功能,保证文件能成功保存。
除此以外,遇到保存路径有重名文件时,该方法也能自动对新文件进行重命名(添加序号),避免路径冲突。
该方法会返回已下载文件的绝对路径,方便程序进一步使用。
Tips
遇到重名时,download()方法可选择skip、overwrite、rename三种方式处理。