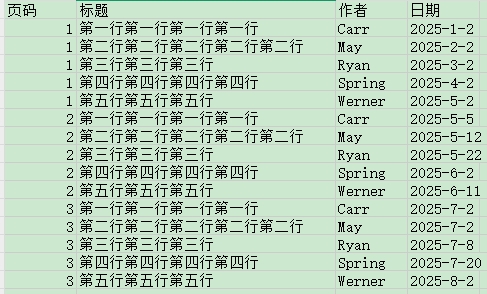
🔖 采集列表数据
本示例以 数据列表 为例演示采集网页列表数据。
✅️ 任务分析
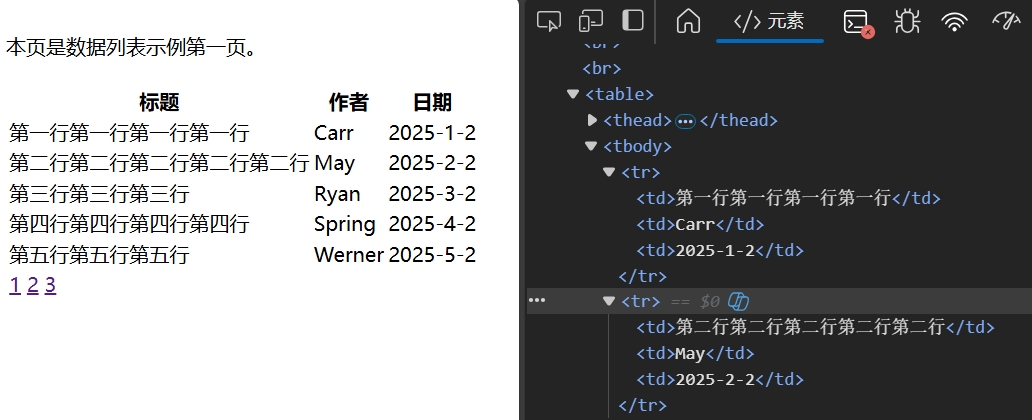
打开网页 F12,可见列表数据保存在<tbody>中,每行 3 列。
可用 DrissionPage 遍历 3 页,读取每页<tbody>内每行内容,并写入到Recorder指向的文件。
每页的数据统一加上页码。
✅️ 完整代码
from DrissionPage import Chromium
from DrissionRecord import Recorder
t = Chromium().latest_tab
r = Recorder('data.xlsx') # 文件如不存在会自动创建
t.get('https://DrissionPage.cn/Demos/list_1.html')
for i in range(1, 4):
r.set.before({'页码': i})
for tr in t('t:tbody').eles('t:tr'):
标题, 作者, 日期 = [td.text for td in tr.eles('t:td')]
r.add_data({'标题': 标题, '作者': 作�者, '日期': 日期})
e = t('下一页', timeout=.5)
if e:
e.click.for_url_change()
r.record()
✅️ 代码解读
每进入一页,用set.before()添加补充列数据,该数据会添加到每条数据前面,为每条数据加上页码信息。
标题, 作者, 日期 = [td.text for td in tr.eles('t:td')]每行有 3 列,提取其内容生成该行数据。
r.add_data({'标题': 标题, '作者': 作者, '日期': 日期})把行数据填入add_data()。
✅️ 执行结果