🔖 拆分数据
本示例演示如何按值拆分表格。
✅️ 任务分析
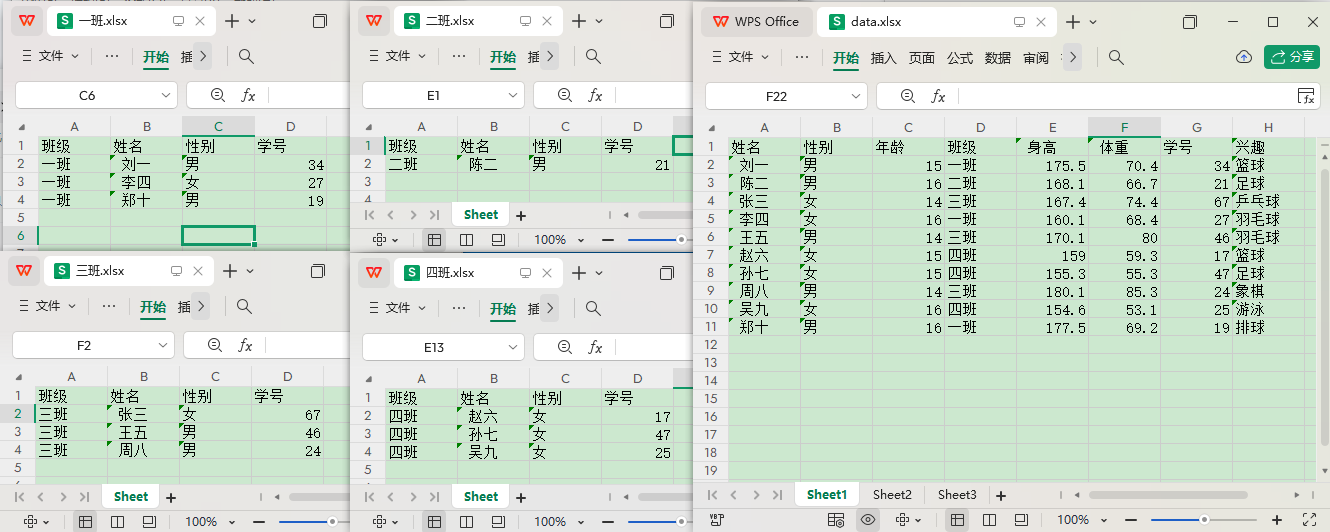
有如下表格文件'data.xlsx'。
| 姓名 | 性别 | 年龄 | 班级 | 身高 | 体重 | 学号 | 兴趣 |
|---|---|---|---|---|---|---|---|
| 刘一 | 男 | 15 | 一班 | 175.5 | 70.4 | 34 | 篮球 |
| 陈二 | 男 | 16 | 二班 | 168.1 | 66.7 | 21 | 足球 |
| 张三 | 女 | 14 | 三班 | 167.4 | 74.4 | 67 | 乒乓球 |
| 李四 | 女 | 16 | 一班 | 160.1 | 68.4 | 27 | 羽毛球 |
| 王五 | 男 | 14 | 三班 | 170.1 | 80.0 | 46 | 羽毛球 |
| 赵六 | 女 | 15 | 四班 | 159.0 | 59.3 | 17 | 篮球 |
| 孙七 | 女 | 15 | 四班 | 155.3 | 55.3 | 47 | 足球 |
| 周八 | 男 | 14 | 三班 | 180.1 | 85.3 | 24 | 象棋 |
| 吴九 | 女 | 16 | 四班 | 154.6 | 53.1 | 25 | 游泳 |
| 郑十 | 男 | 16 | 一班 | 177.5 | 69.2 | 19 | 排球 |
现在需要把不同班的拆分到各自的表格,并且只需保留班级、姓名、性别、学号列。
可以用Recorder的rows()方法,批量读取并筛选出指定列数据,用dict分开记录每个班的数据。
再遍历每个班,用set.path()修改文件路径指向,生成每个班对应的文件。
✅️ 完整代码
from DrissionRecord import Recorder
r = Recorder('data.xlsx')
所有班 = {}
for row in r.rows(cols=['班级', '姓名', '性别', '学号']): # 指定获取哪些列
所有班.setdefault(row['班级'], []).append(row) # 把所有数据分类存放在字典中
for 班, 学生列表 in 所有班.items():
r.set.path(f'{班}.xlsx')
r.add_data(学生列表)
r.record()
✅️ 代码解读
📌 cols参数
使用rows()方法的cols参数可指定获取的数据包含哪些列,其余列不会出现在数据中。
📌 分类存放数据
把所有学生数据存放到名为所有班的字典中,以班级名为 key。
得到:
所有班 = {'一班': [{'姓名': ' 刘一', '学号': 34, '性别': '男 ', '班级': '一班'},
{'姓名': ' 李四', '学号': 27, '性别': '女 ', '班级': '一班'},
{'姓名': ' 郑十', '学号': 19, '性别': '男 ', '班级': '一班'}],
'三班': [{'姓名': ' 张三', '学号': 67, '性别': '女 ', '班级': '三班'},
{'姓名': ' 王五', '学号': 46, '性别': '男 ', '班级': '三班'},
{'姓名': ' 周八', '学号': 24, '性别': '男 ', '班级': '三班'}],
'二班': [{'姓名': ' 陈二', '学号': 21, '性别': '男 ', '班级': '二班'}],
'四班': [{'姓名': ' 赵六', '学号': 17, '性别': '女 ', '班级': '四班'},
{'姓名': ' 孙七', '学号': 47, '性别': '女 ', '班级': '四班'},
{'姓名': ' 吴九', '学号': 25, '性别': '女 ', '班级': '四班'}]}
再遍历每个班,把班的数据插入到以这个班命名的文件中。
📌 插入并保存数据
r.add_data(学生列表)中,学生列表是二维数据,可以直接用add_data()批量添加到文件。
程序会根据dict的 key 自动为空文件填入表头行。
每次set_path()都会自动保存数据,所以最后只要一次r.record()即可。
✅️ 执行结果